 밍벨로퍼와 함께 AI & Robot 친해지기!
밍벨로퍼와 함께 AI & Robot 친해지기!
** ⏰ 읽는 시간: 20분**
들어가기 전
- Python에서 데이터 분석과 시각화를 쉽게 만들어주는 모듈이 있다.
- Matplotlib으로 그래프 시각화, Scikit-learn 에서 선형 회귀 함수를 사용해서 기본적 데이터 분석을 수행해보겠습니다.
Dataset 다운로드
Python Module Requirement
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import koreanize_matplotlib
from matplotlib.colors import ListedColormap📒 데이터 기초 분석
📌 데이터 전처리
seoul_cctv 라는 이름으로 cctv 설치 현황 데이터를 불러오자.
seoul_pop 라는 이름으로 서울시 인구 현황도 불러올 것이다.
seoul_cctv = pd.read_csv('../data/01_seoul_cctv.csv')
seoul_pop = pd.read_excel('../data/02_seoul_population.xls')혹시, .xls 데이터를 불러오는데 오류가 발생한다면 xlrd를 설치한다.
pip install xlrd- 서울시 인구 현황 상위 5행

seoul_pop.head()- 서울시 CCTV 설치 현황 상위 5행
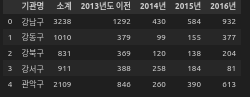
seoul_cctv.head()
seoul_pop 과 seoul_cctv에서 데이터를 필요한 것만 남기자.
# 기관명 칼럼을 구별로 이름 변경
seoul_cctv.rename(columns={'기관명':'구별'}, inplace = True)
# 엑셀 데이터에서 필요한 데이터 칼럼만 남기겠다.
pop_seoul = pd.read_excel('../data/02_seoul_population.xls', header=2, usecols='B, D, G, J, N')
# header=2 : 두번째 index부터 불러오겠다.
# usecols=' ~ ' 해당 column들을 불러오겠다.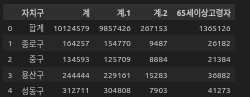
위와 같이 B, D, G, J, N 열에 해당하는 칼럼만 남았다.
이제 이 칼럼의 이름을 알맞게 바꿔주자.
pop_seoul.rename(columns={'자치구':'구별','계':'인구수','계.1':'한국인','계.2':'외국인','65세이상고령자':'고령자'},inplace=True)
# inplace=True : 해당 변수에 변경 사항을 저장하겠다. False 시 저장 안되고, 일시적으로 출력만 됨.Q : 인구수가 가장 많은 상위 5개 구는?
seoul_pop.sort_values(by="인구수",ascending=False, inplace=True).head()
# head = 상위 5개 출력. 괄호에 숫자 입력으로 표시 갯수 조절 가능. (ex: .head(10) -> 상위 10개 출력)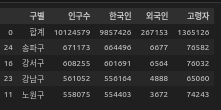
# 합계 index를 제거 후 상위 5개 출력
seoul_pop.drop([0], axis=0, inplace=True) # 0번 인덱스인 합계 삭제
#axis=0 : 가로 방향으로 삭제하겠다. 1은 세로.
# 상위 5개 행만 출력하자.
seoul_pop = seoul_pop.head()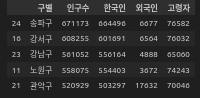
# 외국인과 고령자 비율 칼럼을 추가하자.
pop_seoul['외국인비율'] = pop_seoul['외국인'] / pop_seoul['인구수'] * 100
pop_seoul['고령자비율'] = pop_seoul['고령자'] / pop_seoul['인구수'] * 100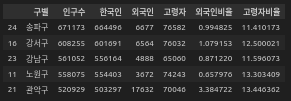
📌 인구수 & CCTV 데이터 합치기
두 데이터를 쓰기 편하게 merge기능을 활용해 필요없는 칼럼은 drop 으로 버린 뒤, 합쳐줄 것이다.
data_result = pd.merge(seoul_cctv, pop_seoul, how='inner',on='구별')
data_result.drop(['2013년도 이전','2014년','2015년','2016년'], axis = 1, inplace=True)
# merge : 가로 기준으로 두 데이터를 병합.
# how='inner' : 교집합만 남긴다. ('outer' : 합집합 전체 출력)
# on='구별' : '구별'이라는 index를 기준으로 how대로 병합을 수행한다.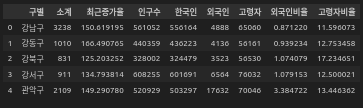
여기서 소계가 CCTV 설치 갯수이다.
📒 데이터 시각화
📌 Matplotlib : 데이터 그래프화
import koreanize_matplotlib # 한국어 지원 matplotlib 모듈
# 그래프 화질이 더 선명하게 보이게하려면 아래 두줄 추가.
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# 인구수 칼럼을 바 그래프로 그려보자.
data_result['인구수'].sort_values().plot(kind='barh', grid=True, figsize=(10,10))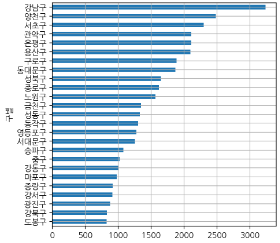
# 인구수 대비 CCTV 갯수를 Scatter로 그려보자.
import matplotlib.pyplot as plt
import koreanize_matplotlib
fig, ax = plt.subplots(figsize=(14, 10)) # 그래프를 담을 창 생성
ax.scatter(data_result['인구수'],data_result['소계']) # x, y 축의 데이터 각각 입력.
ax.grid() # grid 표시
ax.set_title('인구수 대비 CCTV 갯수') # 제목
ax.set_xlabel('인구수') # x축 이름
ax.set_ylabel('cctv') # y축 이름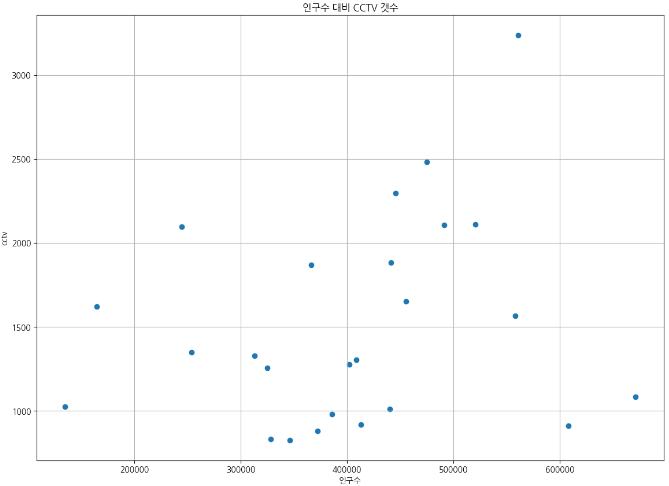
Q : 어떤 점이 무슨 지역인지 모르겠어요! 데이터 직관성도 떨어지구요.
A : 선형 회귀 그래프와 Colormap, text 삽입을 통해 해결해보자.
📌 Scikit-learn : 선형 회귀
from sklearn.linear_model import LinearRegression
# 모델에게 줄 입력데이터와 출력데이터
x = data_result['인구수'].values.reshape(-1,1)
y = data_result['소계'].values
# 회귀분석모델 생성
model = LinearRegression()
# 회귀분석모델 훈련
model.fit(x, y)
predicted = model.predict(x)
plt.figure(figsize=(14, 10))
plt.scatter(data_result['인구수'], data_result['소계'])
plt.plot(x, y, c ='r')
plt.grid()
plt.show();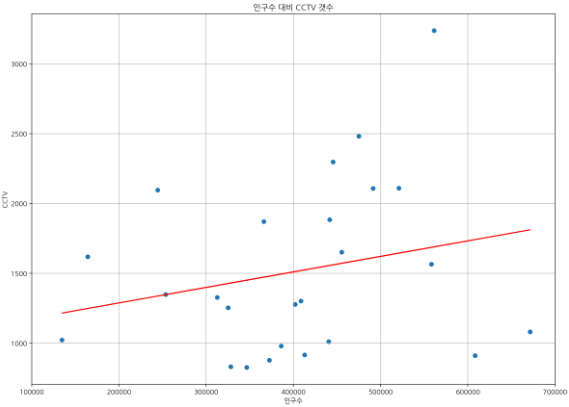
위와 같이, 선형 회귀선은 가로축과 세로축의 관계 및 경향성을 직선으로 나타냄.
📌 Colormap, text로 그래프 꾸미기
# 직선과 점 데이터 간의 거리 (오차)
data_result['오차'] = data_result['소계'] - model.predict(x)
#df_sort_f = 오차를 기준으로 내림차순 정렬한 데이터
#df_sort_t = 오차를 기준으로 오름차순 정렬한 데이터
df_sort_f = data_result.sort_values(by='오차',ascending=False)
df_sort_t = data_result.sort_values(by='오차',ascending=True)
from matplotlib.colors import ListedColormap# google 에 ColorPicker 검색, 맘에드는 색상 Hex값 가져옴.
color_step = ['#eb3434', '#eb7434', '#ebde34', '#37eb34', '#3446eb', '#c034eb']
my_cmap = ListedColormap(color_step)
plt.figure(figsize=(15, 10))
# Scatter 그래프 생성 (c 기준 값 크기 순서대로 cmap에 나열된 색깔 입힘.)
plt.scatter(data_result['인구수'], data_result['소계'], c=data_result['오차'], cmap=my_cmap)
plt.plot(x, y, 'r')
# cctv가 많은 곳 상위 5개 이름 표현
[plt.text(df_sort_f['인구수'][i]+5000, df_sort_f['소계'][i], df_sort_f.index[i]) for i in range(5)]
# cctv가 적은 곳 하위 5개 이름 표현
[plt.text(df_sort_t['인구수'][i]+5000, df_sort_t['소계'][i], df_sort_t.index[i]) for i in range(5)]
plt.ylabel('CCTV')
plt.xlabel('인구수')
plt.title('인구수 대비 CCTV 갯수')
plt.colorbar()
plt.grid()
plt.show();
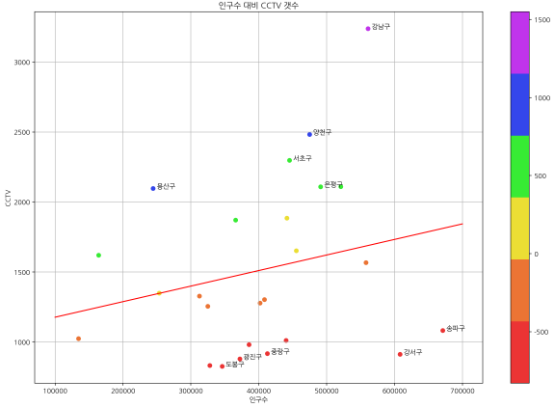
선형회귀 오차에 따라 색깔을 입히고, cctv가 많은 곳 상위 5개, 하위 5개 지역에 text를 추가하여 그래프에 더 많은 정보를 담았다.
이상 데이터 기초 분석 및 그래프 시각화를 해보았습니다.
다음 글에서는 Heatmap 등을 사용한 고급 시각화 그래프를 그려보겠습니다. 😸
'💻️ SW Develop > Data Analysis' 카테고리의 다른 글
| [Web crawling] naver API - 웹 크롤링으로 네이버 쇼핑 아이패드 가격 자동 비교! (5) | 2023.08.17 |
|---|---|
| [Python] EDA를 위한 numpy & pandas 기초 (0) | 2023.08.13 |

