 밍벨로퍼와 함께 AI & Robot 친해지기!
밍벨로퍼와 함께 AI & Robot 친해지기!
** ⏰ 읽는 시간: 20분**
들어가기 전
크롤링(crawling) 이란?
- Web상에 존재하는 Contents를 수집하는 작업 (프로그래밍으로 자동화 가능)
요즘 들어 유용한 주식 자동매매, 빅데이터 수집 및 분석 등이 '웹 크롤링'을 통해 이루어진다.
- HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법
- Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법
- Selenium, BeautifulSoup등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법이처럼 웹 크롤링에는 다양한 기법들이 있지만, 최근 악용하는 사례가 늘어 기업들이 보안으로 막는 추세이다.
따라서, 네이버에서 합법적으로 제공하는 naver API를 활용해 웹 크롤링을 안전하게 수행해보겠습니다.
Python Module Requirement
import urllib.request
import json
import datetime
import matplotlib.pyplot as plt
import seaborn as sns
import koreanize_matplotlib
import numpy as np
import pandas as pd
%matplotlib inline
%config InlineBackend.figure_format = 'retina'네이버 API 등록 절차
- 네이버 개발자 센터 방문 [ 💻️ Naver Developers Link ]

- Open API 이용 신청
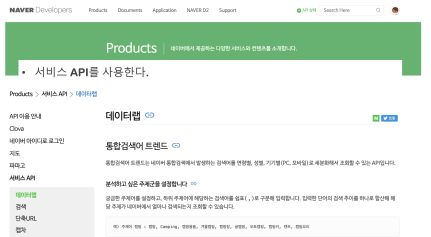
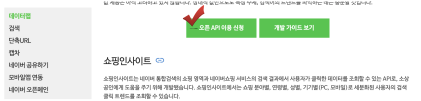
- API 이용 신청
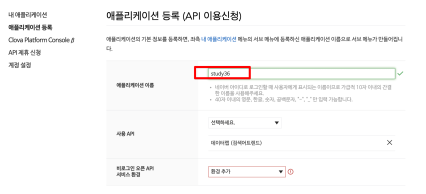
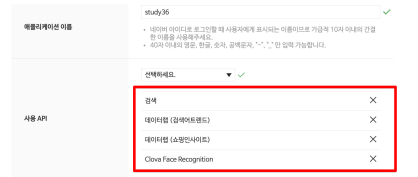
- 웹 설정
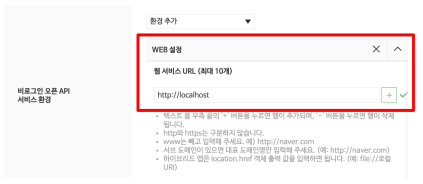
- 등록

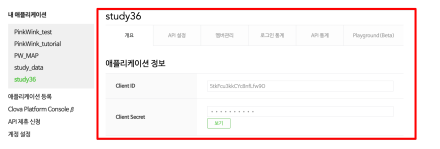
- Client ID, Client Secret 정보를 따로 보관할 것!
📒 웹 크롤링으로 빅데이터 긁어모으기!
📌 네이버 검색 API 연습 (검색어 : 맥북 / 카테고리 : 쇼핑)
client_id = **** (본인의 API 등록 정보)
client_secret = **** (본인의 API 등록 정보)
# 클라이언트가 서버에 요청할 URL 정보 생성
encText = urllib.parse.quote('맥북')
url = 'https://openapi.naver.com/v1/search/shop.json?query=' + encText
# URL 정보로 서버에게 요청과 응답
request = urllib.request.Request(url) # 요청
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request) # 응답
# 응답을 제대로 받았는지 확인
rescode = response.getcode()
#print(rescode)
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)위의 웹 페이지 정보를 요청하고, API에서 응답받아 받아오는 코드에 대한 설명은 분량상 나중에 올리겠습니다.
아래 사진과 같이 직접 손으로 검색해서 일일이 찾아봤던 정보가......
아래와 같이 .json 파일 형식으로 해당 페이지의 데이터가 깔끔하게 들어가있다.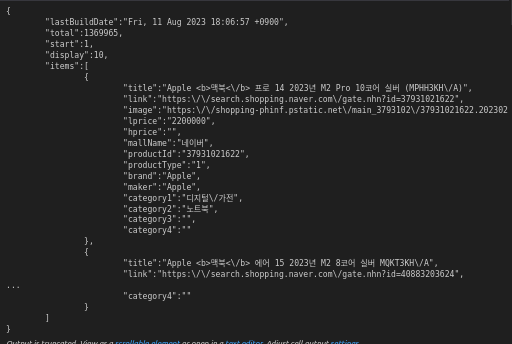
📌 웹 크롤링 자동화
위와 같은 코드로 웹 페이지 정보를 불러오면 끝이 아닌가? 싶지만, 위의 데이터는 해당 페이지의 정보만 포함되어있다.
즉, 사람이 눈으로 한 페이지씩 보는 것과 데이터 양이 똑같다는 것이다. 이러면 크롤링을 하는 이유가 없지 않지 않은가.
🌟 웹 크롤링 코드를 함수화해서 첫 페이지부터 끝번호 페이지까지 해당하는 데이터를 한번에 불러오자!!
def gen_search_url(api_node,search_text,start_num,disp_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + node + param_query + param_disp + param_start
위와 같이, gen_search_url 이란 코드를 생성, 원하는 범위에 해당하는 URL을 반복문을 돌려 계속 바꿔주자.
# 카테고리 : 네이버 쇼핑
# 검색어 : 맥북
# 해당 페이지 : 1 페이지
# 한 페이지에 몇개 보여줄래 : 5개 (최대 100개)
gen_search_url('shop', '맥북', 1, 5)
>>> 'https://openapi.naver.com/v1/search/shop.json?query=%EB%A7%A5%EB%B6%81&display=5&start=1'위와 같이, 내가 원하는 범위가 보이는 페이지의 URL이 생성됐다.
URL이 생성됐다고 끝이 아니다! 이 URL과 API 사용자 헤더 정보를 담아서 네이버에 정보를 요청하고, 원하는 데이터를 받아오는 함수를 만들자. 이 모든 함수들은 크롤링 자동화를 위해 필요한 요소들이다.
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
print(f'{datetime.datetime.now()} Url Request Success')
return json.loads(response.read().decode('utf-8'))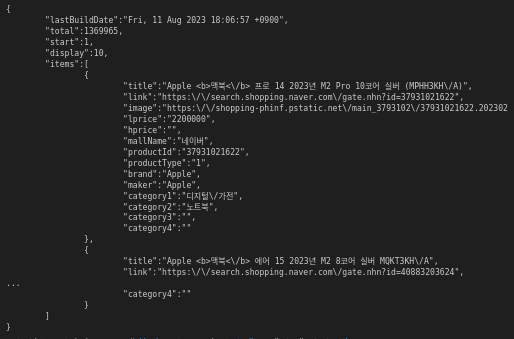
위의 json 파일에서 원하는 정보만 어떻게 가져올까? 데이터 형태를 유심히 봐보자. {}로 감싸져있는 것도 있고, []로 감싸져 있는 것들도 있다.
무언가 느낌이 오지 않는가? 그렇다. 파이썬 데이터 타입 중 딕셔너리와 리스트 타입이다!!
따라서, 아래와 같이 필요한 데이터만 추출해서 Pandas DataFrame 형태로 저장하자.
이때 <b> 등 불필요한 문자열등이 보이는데, 이를 제거해주기 위해 delete_tag 라는 함수도 선언해주자.
def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
input_str = input_str.replace('\xa0', '')
return input_str
def get_fields(json_data):
title = [delete_tag(each['title']) for each in json_data['items']]
link = [each['link'] for each in json_data['items']]
lprice = [each['lprice'] for each in json_data['items']]
mall_name = [each['mallName'] for each in json_data['items']]
result = pd.DataFrame({
'title': title,
'link': link,
'lprice': lprice,
'mall': mall_name,
}, columns=['title','lprice','mall','link'])
return result이제 필요한 모든 함수는 선언 완료! 이제 for문을 사용해서, 100개씩 10번 가져와 1000개의 데이터를 크롤링해보겠습니다.
원래 목적이었던 아이패드를 검색어로 입력!
result_datas = []
for n in range(1, 1000, 100):
url = gen_search_url('shop', '아이패드', n, 100)
json_result = get_result_onpage(url)
result = get_fields(json_result)
result_datas.append(result)
# 리스트로 저장된 데이터셋을 concat 함수로 모두 병합해주고, reset_index로 인덱스를 초기화해 0부터 정렬되도록 하자.
result_datas_concat = pd.concat(result_datas)
result_datas_concat.reset_index(drop=True, inplace=True)
# 필요하다면 csv 파일로 데이터를 저장할 수도 있다.
result_datas_concat.to_csv('원하는 지정 경로/Naver_shopping.csv', sep=',', encoding="utf-8")이제 데이터가 잘 나왔는지 출력해볼까?
result_datas_concat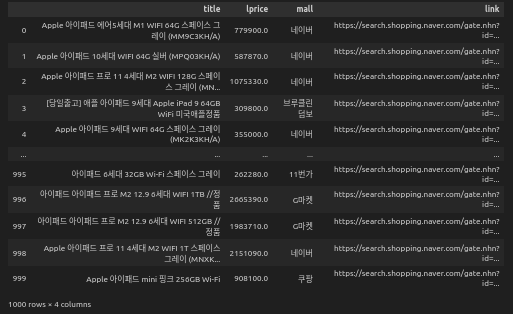
📌 데이터 전처리
.info() 함수를 사용하여 데이터가 목적대로 잘 들어갔는지 확인해보자.
result_datas_concat.info()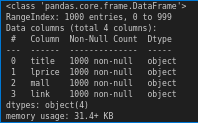
데이터 갯수는 1000개 전부 누락된 값 없이 잘 들어갔고.. 근데 가격 (lprice) 칼럼의 데이터 타입이 object 네!?
➡️ object란? pandas에서 str, 즉 문자열이라고 생각하면 편하다. 숫자형이어야 하는 가격이 문자열로 들어가있으니 잘못됐다!
result_datas_concat['lprice'] = result_datas_concat['lprice'].astype(np.float64)위 코드와 같이, 가격 칼럼의 데이터형을 float로 바꿔주자.
이제, 1000개 품목 (1000 rows) 에 해당하는 title (상품명), lprice (가격), mall (판매처), link (판매처 링크) 모두 잘 저장됐다.
웹 크롤링은 이제 끝이다!!
이제 이를 활용하여 데이터 분석을 수행해볼까?
📒 웹 크롤링 데이터 분석 및 시각화!
📌 기초적 데이터 분석 및 활용
우선, 데이터의 기초적인 통계를 describe() 함수를 통해 알아보자.
result_datas_concat.describe() # 숫자 데이터 칼럼만 분석해준다.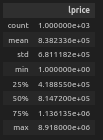
- 평균 : 83만원
- 최솟값 : 1원..? (개통 약정이 붙어있는 상품 자체 가격은 1원으로 올라오더라!)
- 최댓값 : 890만원...!?
1원은 개통 약정이라고 하자. 그렇다면 890만원에 판매하는 곳은 대체 어떤 곳일까?
result_datas_concat[result_datas_concat['lprice'] > 8e+06]
범인은 바로 옥션이었다! 이게 정말일까? 링크를 클릭해서 들어가보면...
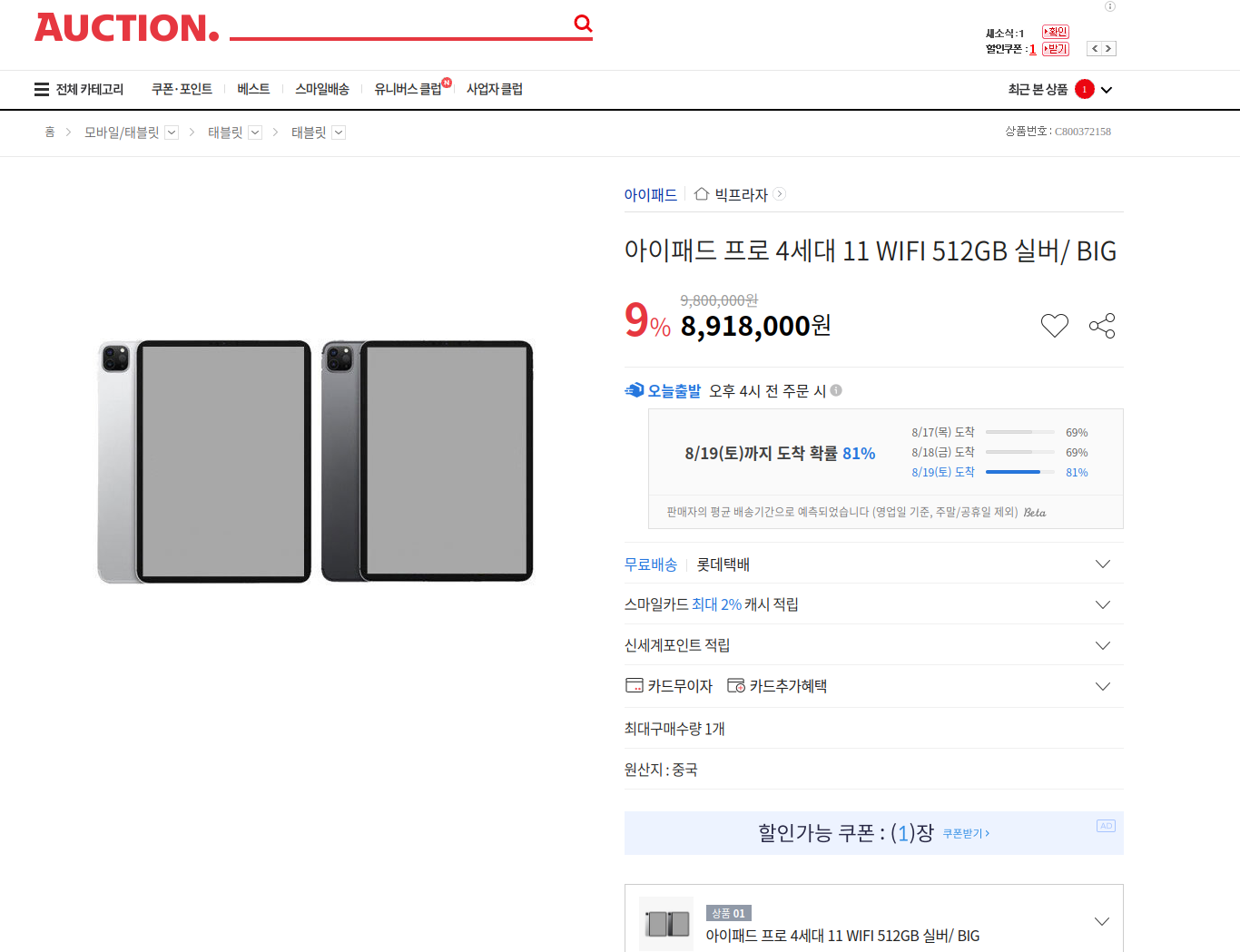
ㅋㅋㅋ 실제로 890만원에 판매중이다! 이 가격에 파는 이유를 아시는 분은 댓글로 알려주시면 감사드리겠습니다 ㅎ
📌 데이터 시각화
그렇다면, 1000개의 상품 중 어떤 판매처가 제일 많은 품목을 판매하고 있을까?
mall_values = result_datas_concat["mall"].value_counts().sort_values(ascending=False).index.tolist()
result_datas_concat["mall"].value_counts().sort_values(ascending=False).plot(
kind="bar",
figsize=(15, 10),
xticks=range(len(mall_values)),
rot=90
)
plt.xticks(range(len(mall_values)), mall_values);
plt.show();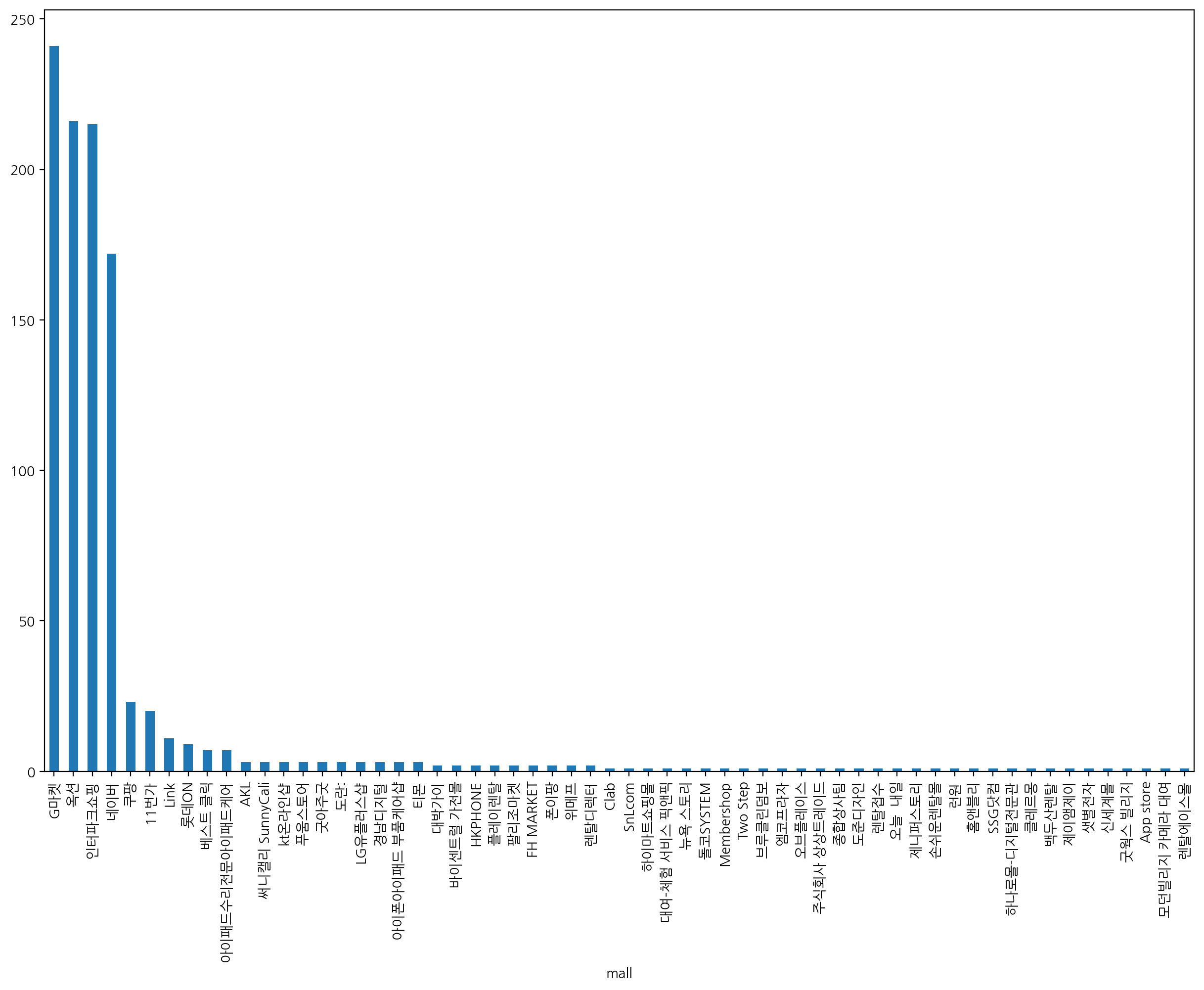
G마켓, 옥션, 인터파크쇼핑, 네이버 쇼핑 품목이 네이버에서 대부분 검색되는 것을 알 수 있다.
이제, 가격 분포를 boxplot을 사용해서 알아볼까?
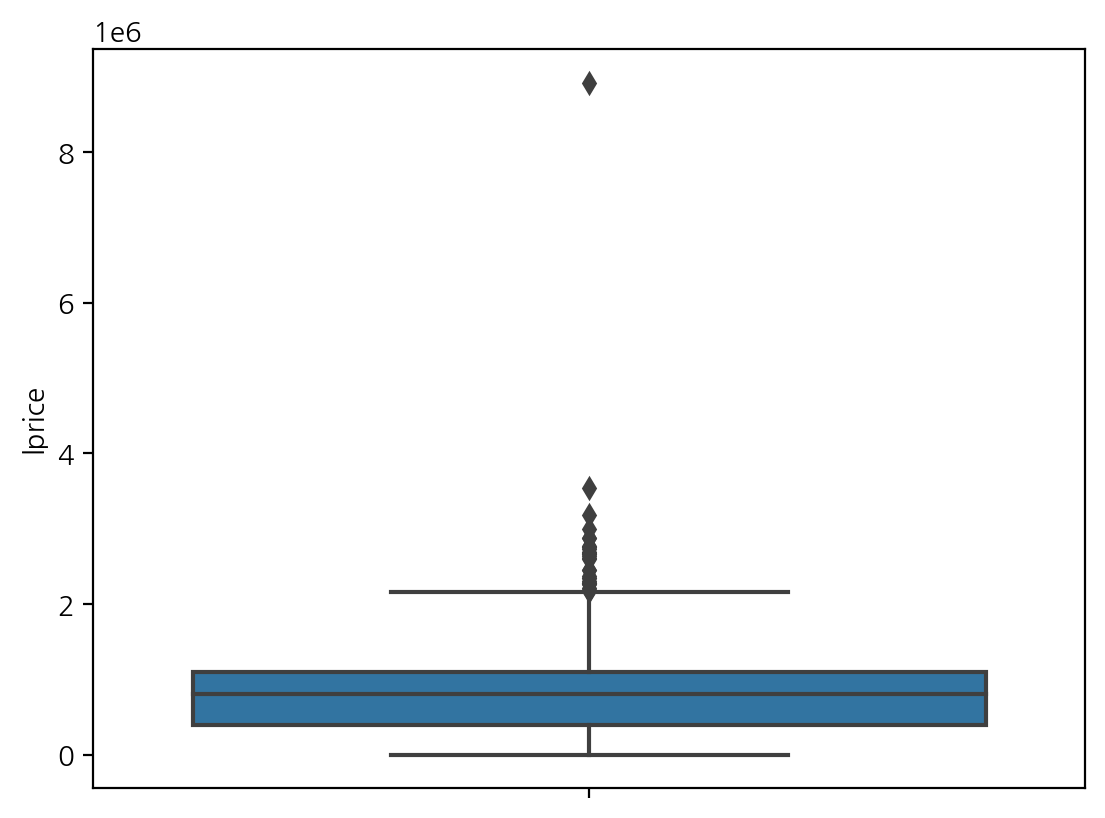
파란색 범위는, 오름차순으로 값을 정렬했을때, 25% ~ 75% 에 해당하는 수치 영역이다. 안에 빨간선은 중앙값(median) 이다.
위 아래로 감싸는 검은선 영역은 허용치 영역이며, 이를 벗어나는 항목들은 이상치(Outlier)로 판단하고 검은 다이아로 표시된다.
boxplot이 생소하다면, 아래 링크에 boxplot에 대한 정보가 나와있다.
🌟 Boxplot 과 친해지기!
이상, 네이버 API를 활용하여 웹 크롤링을 하는 방법과, 긁어모은 데이터로 기초적 분석과 시각화까지 수행해봤습니다. 😎
'💻️ SW Develop > Data Analysis' 카테고리의 다른 글
| [Python] 서울시 CCTV 데이터 분석 - Matplotlib & Scikit-learn 활용 (0) | 2023.08.14 |
|---|---|
| [Python] EDA를 위한 numpy & pandas 기초 (0) | 2023.08.13 |

