 밍벨로퍼와 함께 AI & Robot 친해지기!
밍벨로퍼와 함께 AI & Robot 친해지기!
** ⏰ 읽는 시간: 20분**
들어가기 전
- Python에서 데이터를 다루고 분석하기 위해서는 수만개의 데이터셋을 불러오고 가공하고 분석해야 한다.
- 이러한 데이터 분석(EDA) 에 필요한 기능은 Python에서 지원을 많이 해주고, 거의 필수적인 모듈이 바로 Numpy, Pandas 이다.
- Numpy, Pandas 기초 사용법을 알아보겠습니다.
Python module 설치
pip install python pip install pandas
우선적으로, 두 모듈 설치를 Python Terminal 에서 해주자. (이미 설치되어 있다면 already installed로 나옴.)📒 Numpy 기초 문법
Numpy를 사용하는 주 목적은 행렬 데이터를 처리함에 있고, 이해하기 위해 기초적인 선형대수 내용을 첨부한다.
선형대수
- 스칼라 (scalar)
- 하나의 숫자로만 이루어진 데이터
- 스칼라 1
- 벡터 (vector)
- 여러 개의 숫자가 특정한 순서대로 모여 있는 것
- 벡터 ([1, 2, 3])
- $\mathbf{v} = \begin{bmatrix} 1 \ 2 \ 3 \end{bmatrix}$
- 행렬 (matrix)
- 2차원 배열로 구성
- 행(rows)과 열(columns)
- 행렬 ([[1, 2, 3], [4, 5, 6]])
📌 ndarray 객체 생성
위에서 np로 모듈을 선언한 대로, np.array() 명령어를 사용합니다.
scalar = np.array(5)
scalar
>>> array(5)
vector = np.array([1, 2, 3])
vector
>>> array([1, 2, 3])
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
matrix
>>> array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])📌 배열의 크기 확인
위에서 선언한 변수 그대로 사용합니다.
scalar.ndim, vector.ndim, matrix.ndim
>>> (0, 1, 2)💡 스칼라, 벡터, 행렬에 따라 차원 (0, 1, 2) 가 출력됨. 행렬의 경우 2가 아닌, 그 이상의 차원도 가능.
matrix = np.array([[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]])
matrix.ndim
>>> 3위와 같이 (3,3,2)의 3차원 행렬의 경우, 차원이 3으로 출력됨.
📌 데이터 타입 변경
astype이라는 명령어를 사용합니다.
np.array([1, 2, 3, '4']).astype(np.float64)
>>> array([1., 2., 3., 4.])💡 위와 같이 astype으로 int,str 데이터를 모두 float로 바꿔줌.
📌 특정한 규칙의 ndarray 생성하기
- np.arange(start,end,stride(간격))
💡 파이썬 기본 함수인 range()와 유사하다. 시작, 끝 (정확히는 끝-1의 인덱스), 간격을 설정해 줄 수 있다.
np.arange(5)
>>> array([0, 1, 2, 3, 4])
np.arange(1, 5)
>>> array([0, 1, 2, 3, 4])
np.arange(1, 5, 2)
>>> array([1, 3])- np.zero(), np.ones()
💡 각각 0과 1로 채워진 원하는 크기의 행렬을 만듭니다. 초기값의 행렬을 선언할때 많이 사용함.
np.zeros((2, 2, 3))
>>> array([[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]])2행 3열 크기의 2차원 행렬 2개를 포함한 ndarray를 선언함. zeros는 모든 값이 0으로 채워짐.
np.ones((2, 2, 3))
>>> array([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]])마찬가지로, 설정한 크기만큼의 1로 채워진 행렬 데이터를 생성함.
- np.linspace()
💡 시작값과 종료값 사이에서 지정된 갯수만큼 균등간격으로 선형적으로 분포하는 값 생성
💡 endpoint: True이면, stop값을 배열에 포함
np.linspace(start, stop, [사잇값 갯수] num=50 (default), endpoint=True (default))np.linspace(10, 20, 5, endpoint=False)
>>> array([10., 12., 14., 16., 18.])
np.linspace(10, 20, 5, endpoint=True)
>>> array([10. , 12.5, 15. , 17.5, 20. ])📌 랜덤한 값의 ndarray 생성하기
np.random.randint()
💡 정수 데이터 타입을 균일분포로 생성
np.random.randint(10, size=(2,3)) # 2행 3열의 0부터 9까지 요소의 랜덤 행렬 생성
>>> array([[7, 2, 2],
[0, 1, 2]]) -> 실행할 때마다 배열 달라짐.np.random.seed()
💡 seed 값을 고정하면 동일한 랜덤값 출력 (아무 값이나 상관없음.)
np.random.seed(13)
np.random.randint(0, 10, 10)
>>> array([2, 0, 0, 6, 2, 4, 9, 3, 4, 2]) -> 다시 실행해도 같은 배열이 출력됨.np.random.choice()
💡 반환할 배열의 각 요소의 값이 출력될 확률을 지정 가능
np.random.choice(5, 10, p=[0.1, 0, 0.3, 0.6, 0]) # 0부터 4까지 각각의 확률로 10개 뽑음.
>>> array([3, 3, 3, 0, 3, 2, 3, 3, 3, 0]) # 확률이 0인 1과 4는 출력이 아예 안됨.
np.random.choice([1,3,5,7,9], 10, p=[0.1, 0, 0.3, 0.6, 0]) #
>>> array([1, 1, 7, 7, 7, 5, 5, 7, 7, 1]) #1, 3, 5, 7, 9를 각각의 확률로 출력📌 ndarray 배열의 슬라이싱
# 0부터 9까지 랜덤한 정수값을 가진 열 벡터 생성
vec = np.random.randint(10, size=(2,3))
vec
>>> array([[8, 7, 5],
[4, 2, 5]])
# 처음부터 시작하고, 3번째 인덱스 값 까지 선택해주세요
vec[:3]
>>> array([1, 2, 3])
# 역순에서 3번째 값부터 시작하고, 끝까지 선택
vec[-3:]
>>> array([8, 0, 1])
# 역순에서 4번째 값
vec[-4]
>>> 7
# 처음부터 끝까지 데이터를 선택하는데, 역순으로 2단계씩 건너띄어주세요
vec[::-2]
>>> array([1, 8, 7, 6, 2])
mat = np.random.randint(5, size=(3, 3))
>>> array([[1, 2, 4],
[4, 4, 3],
[2, 3, 4]])
mat[0] # mat 행렬의 1행 출력
>>> array([1, 2, 4])
mat[0][1] # mat 행렬의 1행 2열 원소 출력
>>> 2
mat[0, 1] # 위 인덱싱과 동일한 1행 2열 표현의 다른 방법 (numpy 한정)
>>> 0📌 원하는 형태로 행렬을 변환하기
np.reshape()
vec = np.arange(1,26)
vec
>>> array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25])
mat = vec.reshape(5, 5) # 25개 원소의 열벡터를 5x5 의 행렬 형태로 변환
mat
>>> array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
# 첫 번째 행 전체 선택
mat[0, :]
>>> array([1, 2, 3, 4, 5])
# 세 번째 열 전체 선택
mat[:, 2]
>>> array([ 3, 8, 13, 18, 23])
# 두 번째 행부터 세 번째 행
# 두 번째 열부터 세 번째 열
mat[1:3,1:3]
>>> array([[0, 2],
[4, 4]])
# 행을 역순으로 변환
mat[::-1, :]
>>> array([[21, 22, 23, 24, 25],
[16, 17, 18, 19, 20],
[11, 12, 13, 14, 15],
[ 6, 7, 8, 9, 10],
[ 1, 2, 3, 4, 5]])
# reshape 에서 -1 인덱스의 의미
# 행은 3개로 설정하는데, 열은 자동으로 설정
a = np.arange(9)
>>> array([0, 1, 2, 3, 4, 5, 6, 7, 8])
np.reshape(a, (3, 3)) or a.reshape(3, 3) (둘 중 선택 자유)
>>> array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
# 열이 몇개로 나눠질지 모르겟어요. -> -1 인덱싱을 사용하면 자동으로 지정함.
a.reshape(3, -1)
>>> array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]) -> 위와 동일한 결과!
# 이미지 데이터
image = np.random.randint(0, 255, size=(32, 32, 3), dtype=np.uint8)
image.shape # 가로 32픽셀, 세로 32픽셀, 채널 3개 (R,G,B)
>>> (32, 32, 3)
# 위의 image를 2차원 배열로 변환
# 2차원 배열로 변환
image.reshape(32*32,3)
>>> array([[165, 52, 240],
[133, 29, 167],
[115, 68, 21],
...,
[ 52, 163, 14],
[221, 218, 107],
[ 74, 101, 38]], dtype=uint8)📌 조건에 따른 배열의 요소를 선택하기
np.where()
np.where(condition, x, y)- 조건에 따라 값을 선택
- condition
- 조건을 나타내는 배열 또는 조건문
- True or False
- x, y 는 서로 동일한 크기(shape) 배열 형태
- condition 이 True 인 경우 x 값 반환
- condition 이 False 인 경우 y 값 반환
condition = [True, False, True]
x = [1, 2, 3]
y = [10, 20, 30]
np.where(condition, x, y)
>>> array([ 1, 20, 3])📒 Pandas 기초 문법
- pandas 는 데이터 분석과 조작(전처리)을 위한 오픈소스 라이브러리
- Series 와 DataFrame 이라는 데이터 타입을 이용
- 데이터 필터링, 정렬, 그룹화, 결측치처리, 시각화 등
- Pandas 데이터 타입
- Series
- index, values로 이루어진 데이터 타입
- DataFrame
- index, values, columns 으로 이루어진 데이터 타입
- Series 데이터가 모이면 DataFrame
- tabular, table
- Series
📌 첫번째 데이터 타입, Series
- Series 선언
series = pd.Series([1, 2, 3, 4]) series >>> # 첫번째 열은 index, 두번째 열은 values 0 1 1 2 2 3 3 4 dtype: int64- Series 인덱싱
series[0], series[3], series[1:3], type(series[2])
(1, # 첫번째 values
4, # 네번째 values
1 2
2 3 # 2 ~ 3 번째 values
dtype: int64,
numpy.int64) -> Pandas는 Numpy 모듈을 기반으로 하기에, data type도 Numpy가 출력됨.
📌 시리즈 내부 데이터 타입 변경
pd.Series([1, 2, 3], dtype=np.float64)
0 1.0
1 2.0
2 3.0
dtype: float64
series.astype(np.int16)
0 1
1 2
2 3
3 4
dtype: int16
📌 index 이름 재설정
data = pd.Series(np.random.randint(10, size=5), list('ABCDE'))
data
A 9
B 6
C 1
D 3
E 8
dtype: int64
📌 Series 추가 인덱싱 방법
data['A'], data.A, data[['A','B']] # A 인덱스 출력, A 인덱스 출력, A,B 인덱스 출력
7
7,
A 7
B 5
dtype: int64)
📌 조건문을 활용한 인덱싱
data[data > 5] = 999
data
A 999
B 999
C 999
D 999
E 1
dtype: int64
📌 브로드 캐스팅 연산
data * 100
A 99900
B 99900
C 99900
D 99900
E 100
0 1.0dtype: int64
📌 두번째 데이터 타입, DataFrame
- DataFrame()
- index, values, columns
# 날짜 정보로 인덱스 설정
dates = pd.date_range('20230804', periods=6)
dates
>>> DatetimeIndex(['2023-08-04', '2023-08-05', '2023-08-06', '2023-08-07',
'2023-08-08', '2023-08-09'],
dtype='datetime64[ns]', freq='D')
# 위에서 설정한 index와 4개의 Columns를 가지고 6x4의 DataFrame을 생성
df = pd.DataFrame(data=np.random.randn(6, 4),
index=dates,
columns=['A','B','C','D'])
df
>>> (아래의 사진 출력 - Jupyter notebook 기준)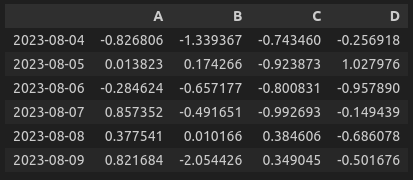
# 데이터 프레임 상단 정보 확인
df.head() # 내가 가진 데이터의 상단 5개만 보여줌.
>>> (아래의 사진 출력 - Jupyter notebook 기준)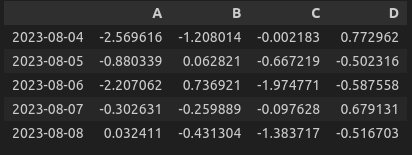
df.head(2) # 상단 2개만 보여줌.
>>> (아래의 사진 출력 - Jupyter notebook 기준)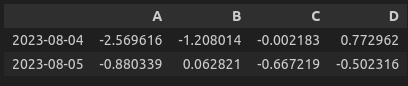
# 데이터 프레임 하단 정보 확인
df.tail() # 하단 5개 보여줌.
>>> (출력 생략)
df.tail(1) # 하단 1개 보여줌 (출력 생략)
# 데이터 프레임 기본 정보 요약
df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 6 entries, 2023-08-04 to 2023-08-09
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 6 non-null float64
1 B 6 non-null float64
2 C 6 non-null float64
3 D 6 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytes
# 데이터 프레임 기술통계 정보 요약
df.describe()
>>> (아래의 사진 출력 - Jupyter notebook 기준)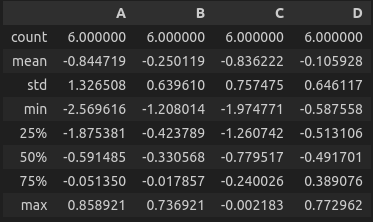
# 데이터 프레임 구성 3요소
df.index, df.columns, df.values
>>> (출력 생략, 각 요소의 배열이 출력됨.)
df.A, df['B'], df[['B','D']]
>>> 각각 A Column의 요소들, B Column의 요소들, B와 D Columns의 요소들이 출력됨. (생략)# 1 ~ 2 번째의 인덱스 요소들을 출력함.
df[0:2]
>>> (아래의 사진 출력 - Jupyter notebook 기준) 
# 1 ~ 3 번째의 인덱스 요소들을 출력함.
df['2023-08-04':'2023-08-06']
>>> (출력 생략)# loc 을 사용한 index와 Columns 동시에 접근하기
df.loc['2023-08-04':'2023-08-06', 'A':'C']
>>> (아래의 사진 출력 - Jupyter notebook 기준)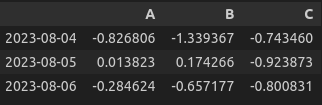
# 숫자로 인덱스 접근하고 싶을땐? iloc을 사용함.
df.iloc[0:2, 1:4]
>>> 위와 동일한 결과 출력함.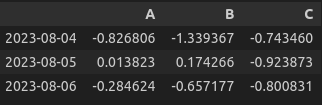
# 데이터 정렬
# sort_values()
df.sort_values(by='A') #'A' 칼럼 기준으로 오름차순 정렬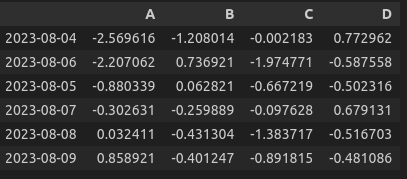
df.sort_values(by='A', ascending=False) # True 오름차순, False 내림차순
>>> (출력 생략)# 동시에 여러열을 기준으로 정렬하고 싶다면?
# A 열을 기준으로 내림차순 정렬하고, 같은 값이 있다면 B 열의 내림차순 기준으로 정렬함.
df.sort_values(by=['A','B'], ascending=False)
>>> (출력 생략)# 데이터를 딕셔너리의 리스트로 생성
data = {
'A' : [1, 2, 3, 4, 5],
'B' : [3, 2, 3, 1, 2],
'C' : [5, 4, 3, 2, 1]
}
# 데이터를 리스트의 딕셔너리로 생성
data = [
{'A': 1, 'B': 3, 'C': 5},
{'A': 2, 'B': 2, 'C': 4},
{'A': 3, 'B': 3, 'C': 3},
{'A': 4, 'B': 1, 'C': 2},
{'A': 5, 'B': 2, 'C': 1},
]
pd.DataFrame(data)
>>> (두 방법 다 같은 결과 출력)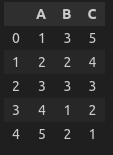
# 컬럼 추가
# 기존에 컬럼이 없으면 추가, 있으면 덮어쓰기
df['E'] = ['one','one','two','three','four','seven']
>>> (아래의 사진 출력 - Jupyter notebook 기준)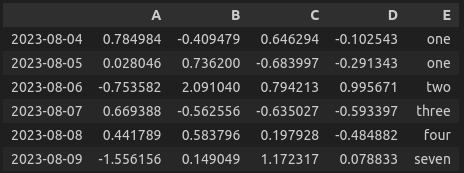
# 데이터 삭제
# 가로 세로 중에 뭘 삭제할껀데? axis 0은 가로, 1은 세로
# in-place 내부 내용을 바꾼다. (즉, 바뀐 값 저장)
df.drop('A', axis=1, inplace=True)
>>> (아래의 사진 출력 - Jupyter notebook 기준)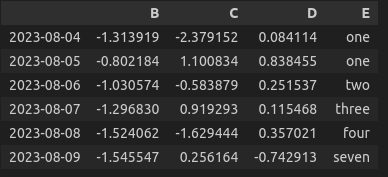
# 가로의 배열 삭제
df.drop('2023-08-06', axis=0)
>>> (아래의 사진 출력 - Jupyter notebook 기준)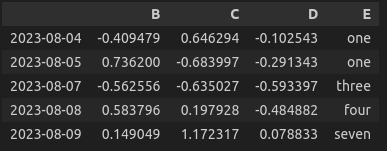
# 가로로 여러 배열 삭제
df.drop(['2023-08-06','2023-08-09'], axis=0)
>>> (출력 생략)
# index= 옵션을 사용해 가로 배열 삭제
df.drop(index=['2023-08-04'])
>>> (출력 생략)
# columns= 옵션을 사용해 세로 배열 삭제
df.drop(columns=['B','D'])
>>> (출력 생략)
# DataFrame 요소들에 함수를 적용하고 싶어요.
# .apply() 사용
def plus_minus(values):
return 'plus' if values > 0 else 'minus'
df['B'] = df['B'].apply(plus_minus)
>>> 함수가 적용되어 0보다 큰건 'plus', 작은건 'minus' 출력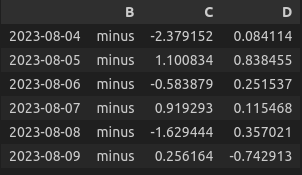
# DataFrame 의 요소값 수정
df.loc['2023-08-06','C'] = 0
df.iloc[1,0] = 0
>>> (결과 생략)
# merge
# 데이터 프레임을 가로로 병합
pd.merge(df1, df2, how='outer or inner (default = inner)', on='id')
# how에서 outer는 합집합, inner는 교집합 요소들만 출력, on을 기준으로 수행. (on이 None이면 모든 요소들에 대해 수행)
pd.merge(left_df, right_df, on='key')
>>> (결과 생략, key를 기준으로 교집합 출력)
pd.merge(left_df, right_df, on='key', how='outer')
>>> key를 기준으로 합집합 출력. 어느 한쪽이라도 데이터가 없으면 NaN값이 지정.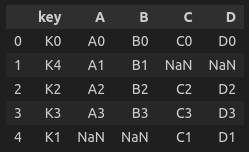
# concat
# 세로로 병합
# NaN : Not a Number (누락 데이터, 누락값)
nan_df = pd.concat([left_df,right_df])
>>> (결과 생략, 세로로 병합됨.)
nan_df.dropna() #Nan값이 있는 해당 index의 데이터를 제외함.
>>> (출력 생략)
nan_df.fillna('누락값') # NaN 값을 괄호안의 요소로 대체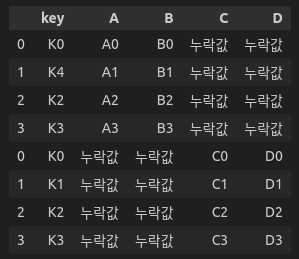
이상 Numpy, Pandas 에서 기초적인 문법들을 알아보았습니다.
다음 글에는 이를 활용하여 데이터 분석 (EDA) 입문 단계를 수행해보겠습니다. 😊
'💻️ SW Develop > Data Analysis' 카테고리의 다른 글
| [Web crawling] naver API - 웹 크롤링으로 네이버 쇼핑 아이패드 가격 자동 비교! (5) | 2023.08.17 |
|---|---|
| [Python] 서울시 CCTV 데이터 분석 - Matplotlib & Scikit-learn 활용 (0) | 2023.08.14 |

